
A partir du moment où l’on s’intéresse au SEO pour développer son site internet ou en qualité de professionnels et aux moteurs de recherche, on ne peut pas ignorer les concepts de balisage et cocon sémantique, les données structurées, rich snippets ou autres Schema.org. Au cœur du fonctionnement des moteurs de recherche, il est fondamental de comprendre les techniques et savoir les intégrer dans vos contenus. La sémantique appliquée au WEB ou syntaxe, l’importance de cette technique à l’heure des graphes de données Knowledge Graph” et “Knowledge Vault”.
Que se cache-t-il vraiment derrière le cocon sémantique ? Quelles sont les bonnes pratiques pour être mieux classés et analysés
que vos concurrents ?
La sémantique appliquée au WEB ou syntaxe
Aujourd’hui la sémantique est partout. Le monde du SEO évolue et contraint par les évolutions des langages, les mises à jour d’algorithmes et les nouvelles capacités des moteurs de recherche. Pour les experts, analystes et outils SEO les plus pertinents, ils parlent de plus en plus decorpus, d’ontologies, de nGram, de balisages schema.org, de thématisations, declusters et cocons sémantiques. Sachez que c’est une bonne pratique pour améliorer la croissance du métier du web tout en restant vigilent aux mutations et en sachant bien faire la part des choses.

Dans un monde en pleine révolution digitale où Google affine ses filtres pour mieux classer les “résultats naturels”, il est plus que nécessaire pour les professionnels du SEO et développeurs de s’adapter et/ou d’évoluer dans cette direction pour en profiter pleinement. On l’a bien compris, les moteurs de recherche deviennent plus intelligents, les crawlers mutent,les indexeurs se « sémantisent… Les développeurs et aujourd’hui tous les acteurs du SEO doivent savoir utiliser les balises sémantiques (main, header, footer, nav, aside, section, balises h1…n,title, meta, em, strong, ul/li, ol/li, dd/dt, figure, blocquote, time, date) pour améliorer la qualité des codes sources. Les balises meta et link ne sont plus réservées aux en-têtes des pages mais jouent le rôle de liaison de métadonnées dans des blocs de contenu.
Quelle est la représentation du cocon sémantique des données structurées pour les moteurs ?
Difficile de se le représenter mais imaginez -vous avoir les yeux d’un moteur de recherche. Vos yeux doivent lire des milliards de balises HTML à la vitesse du son et faire des équations et de calculs complexes. Classer des réponses sur une requête repose pourtant sur des composants logiques : l’algorithme.Toute sa complexité réside dans le fait que vous n’êtes pas un humain mais un robot mais pourtant les utilisateurs le sont. Dans toute cette analyse, il faut comprendre leurs besoins, leurs questions, décoder leurs interrogations. Pas facile d’offrir les contenus adaptés en ne lisant qu’un code source, souvent très dense et souvent mal optimisé au niveau syntaxe sans parler des codes parasites de certaines pages web.
Dans un gain de performance, pour améliorer la capacité d’extraction des meilleurs contenus, il faut simplifier le temps de traitement de l’analyse d’une page. Depuis toujours les moteurs s’efforcent de découvrir des motifs qui se répètent mais pour aller plus loin et faciliter la chose, il faut permettre aux éditeurs de déclarer ce contenu important dans un langage ordonné et hiérarchisé.
Introduction de Schema.org par Google, Bing et Yahoo
Dans cet objectif, en juin 2011, Google, Bing et Yahoo se sont donc unis avec un but : “create and support a common set of schemas for structured data markup on web pages” (source:https://developers.google.com/search/blog/2011/06/introducing-schemaorg-search-engines)
« Nous annonçons aujourd’hui schema.org, une nouvelle initiative de Google, Bing et Yahoo ! visant à créer et à soutenir un ensemble commun de schémas pour le balisage des données structurées sur les pages web. Schema.org se veut une ressource unique pour les webmasters qui souhaitent ajouter des balises à leurs pages afin d’aider les moteurs de recherche à mieux comprendre leurs sites web. »
Si l’on fait un rapide retour en arrière, aux origines du web sémantique existaient les Triplets, issus des premières définitions de RDF (Ressource Description Framework), le modèle de graphe destiné à décrire de façon formelle les ressources web et leurs métadonnées (source Wikipédia
https://fr.wikipedia.org/wiki/Resource_Description_Framework).
Le cocon sémantique existe-t-il vraiment ?
En fait tout le monde en parle, vous en entendez parler mais personne ne l’a vu. Est-ce un mythe ou une réalité ? Est-ce que le web héberge plusieurs cocons sémantiques ? Malheureusement, la plupart des professionnels du SEO ne nous aident pas et c’est clairement exaspérant les tournures utilisées pour le définir notamment en utilisant le terme de « silos lexicaux » . Même si, avouons-le cela peut porter à confusion.
En fait, c’est quoi un cocon sémantique « exactement » ?
Pour le définir succinctement, le cocon sémantique est une stratégie SEO développée par Laurent Bourelly visant à optimiser l’architecture et le maillage interne d’un site web par classification sémantique des contenus en pages mères, soeurs et filles.
Décortiquons les lexèmes de l’expression : cocon sémantique.
Sur le lexème « COCON »
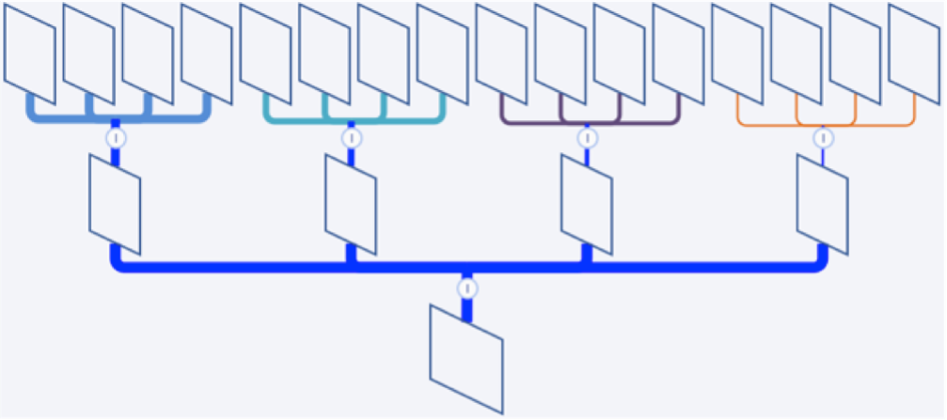
Exemple de structure de cocon sémantique. Credits : reacteur.com Abondance
On comprend que dans ce mindmap , la page à pousser se trouve tout en bas. Les arcs de diverses couleurs, sont les liens dits descendants qui vont des pages à un niveau n, aux pages vers le niveau juste en dessous, n+1. La ressemblance à un silo vient de la représentation mais n’est pas propre au cocon. Le vocable « SILO » est né uniquement de la présentation par mindmap. Le terme cocon ne se réfère pas à une géographie particulière.
Sur le lexème « SÉMANTIQUE »
Là aussi, la confusion est courante entre thématique et sémantique. Dans la réalité, la sémantique se rapporte au sens d’un texte et pas sur sa thématique.
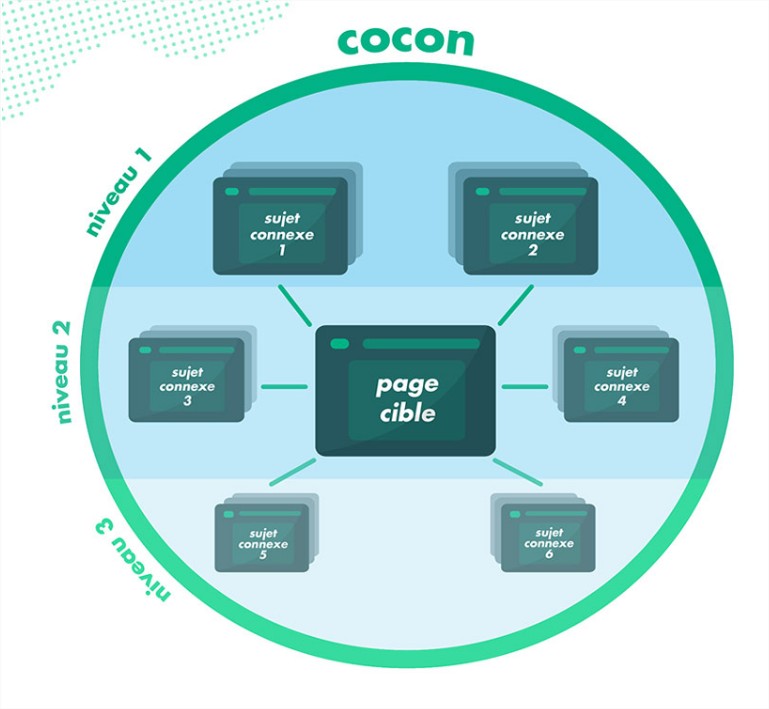
cocon sémantique : page cible et sujets – outils SEOQuantum
Par exemple si on prend la thématique de la musique classique, on peut traiter plusieurs sujets distincts sur cette thématique. Le « sujet » est ce dont parle UNE page précise. Pourtant, nous ne sommes pas encore au niveau de la sémantique. Ce qui sera rédigé dans le sujet aura du sens ou pas. La sémantique est donc le sens du texte. Ce sens est celui du texte lui-même. Si on donne un sujet a travailler à différentes personnes, chacun donnera un texte différents qui auront un sens différents qui se retrouvera dans le texte.
- Pour résumer sur la définition des lexèmes :
Thématique = classement arbitraire d’objets ou concepts.
Sémantique = sens d’un texte, d’un paragraphe, d’une phrase, d’un mot…
Par exemple, pour mettre en avant un pays, nous pourrions développer trois branches :
- la première sur son histoire,
- la seconde sur sa géographie
- la troisième sur ses villes principales et ses activités culturelles
Si en 2012-2013 lorsque Google n’était pas encore assez avancé pour se casser la tête, aujourd’hui relier deux pages de même thématique est insuffisant pour que cela soit incitatif ( clic au lien). Si l’on développe les activités culturelles de la ville, pour atteindre les personnes selon leurs gouts, il faudra faire plus de développements, c’est tout l’art du cocon sémantique.
Pour bien comprendre la notion du sens
Pour illustrer notre propos, prenons la page Wikipedia sur Mozart. Un paragraphe de cette page parle de sa ville de naissance. Celui-ci va naturellement faire un lien vers la page qui parle de Salzbourg. Si le lien est fait ailleurs dans cette page, il peut perdre tout son sens. La thématique « musique classique » a-t-elle le moindre rapport avec la thématique « villes » ? Aucun, cependant, le lien ici fait SENS.
Comment Google perçoit la sémantique ?
Dans la compréhension du sujet des pages et son classement, Google ne le comprend pas comme un humain, c’est qu’une machine ! Mais il a trouvé le moyen d’y remédier en extirpant le nécessaire d’un texte et faire des rapprochements. Quand on appelle ça « machine learning « c’est juste pompeux et une belle tromperie ! Car une machine qui ne comprend rien ne peut rien apprendre, elle ne fait que collectées des données. Pourtant, cela est suffisant pour détecter si les liens entre deux textes font sens pour l’internaute.
Au niveau d’un logiciel, il est possible de programmer un système de prédiction. C’est ce que nous nommons la « sémantique prédictive ». Elle ne donnera pas à la machine le sens car elle ne comprend rien mais elle peut prédire si le visiteur y trouvera ce qu’il cherche. Par exemple, une page soumise peut tenir sa promesse avec un lien conduisant à la recherche.
Et au niveau des référenceurs SEO ?
Cette finesse sémantique soit la puissance du maillage n’est pas largement utilisé et mise en application par la plupart des SEO ou rédacteurs web. Pourtant la contextualisation des liens est meilleure manière de donner des indices à la machine Google pour qu’elle puisse faire ses rapprochements.
Dans ses caractéristiques et sa structure le cocon sémantique moderne doit impliquer :
- Un maillage construit pour amplifier la force de la tête.
- Des sujets de pages bien traités soigneusement avec une création logique de liens. Ce qui implique des contenus hautement qualitatifs et bien balisés
- Des liens de contenu prioritaires par rapport à ceux du menu.
- Insertion d’une table des matières.
La taille du cocon est très importante. Le nombre de pages qu’il contient joue le même rôle que la quantité de liens en netlinking. En sachant qu’un cocon sémantique est bien plus stable vu que vous n’avez aucune raison de perdre vos pages ce qui n’est pas le cas dans une campagne de liens (netlinking).
Soyez toutefois vigilant à ne pas réaliser une action surdimensionnée et usant de qualité faible pour les contenus pourrait être induire des sanctions.